



AMD“Bulldozer”“Bobcat”架构解读
Bulldozer:四路并行解码与多内核制胜
每个时钟周期能并发执行多少条指令,这个硬指标决定了CPU的指令效能——并发3条与并发4条的区别就是高达33%的性能差距。
四路并行解码
长期以来,我们都知道诸如ARM、PowerPC、MIPS等RISC架构的处理器,在指令性能上都远高于同时代的X86芯片,原因就在于RISC体系的指令系统是经过精简优化的,20%的常用指令具优先权,余下80%指令处于次级地位,那么在微架构的设计中,RISC芯片可以轻松做到4发射、也就是并发执行4条指令,而不会影响到频率的提升。与此形成鲜明的对,X86是一种复杂的原始指令,在过去的30年间它都只停留在3指令发射阶段,一旦提高到4指令发射就会严重影响到频率的提升。
Intel的Netburst和AMD的K8体系都是3指令发射,前者不幸拥有长流水线,导致指令效能十分低下。实际上Intel很快就意识到Netburst存在的问题,它让以色列的研发部门完成下一代架构“Merom”、也就是现在的Core架构的设计。Core架构大的特点就是从RISC中吸取营养,它对X86指令进行融合优化、使其变得精简——这样做固然耗费了一定的晶体管资源,但也让Core架构具备4指令发射的能力,也就是Core架构每周期能执行4条指令,而AMD同时期的K10依然只能每周期执行3条指令——这便是AMD处理器在过去数年中性能一直显著落后的关键原因。当然你也会注意到一点,Core架构的工作频率从奔腾4的3.6GHz大幅度降低,即便目前的32纳米工艺,高峰也只是达到3.33GHz而已,这便是4发射设计的副产物。
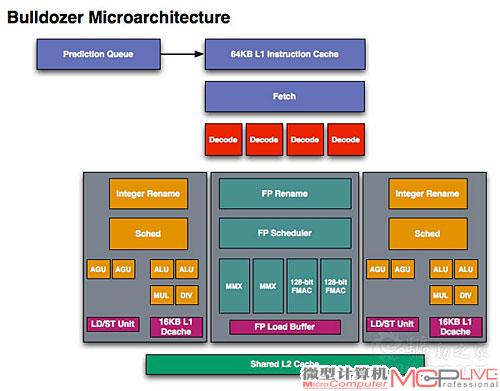
图3 Bulldozer可并行解码四条指令,这将显著提升其指令效能。
如今,即将发布的Bulldozer令人兴奋的地方便在于,它也是一款4指令发射的X86处理器,AMD没有详细解释它是如何做到的,但我们不难猜测,对X86指令的优化仍是唯一的途径,换言之Bulldozer从Intel Core架构的设计中汲取了营养,这也是一条非常正确的道路。而只要具备4指令发射这要素,那么Bulldozer与Core的差距就不会是本质性的、顶多伯仲之间。所以任何对Bulldozer执行效率的担心都比较多余——显然,结合AMD在图形领域的优势,我们不难知道它将迎来K8时代后的第二次崛起。
独特的1.5核心设计
4路并行的指令,终将被送入整数计算单元和浮点计算单元进行处理,整数计算性能体现CPU的事务处理能力高低,比如操作系统、应用软件、服务器程序的运行,都是由整数部分决定的;而图形处理、物理计算、视频编解码等应用涉及到浮点计算能力。
在过去,CPU是PC系统的中枢,整数性能与浮点性能同样重要,为此CPU内一般拥有相同的整数计算单元和浮点计算单元。但如你所见,今天的情况已经大不相同:GPU接管了大量的浮点运算,CPU的任务更多偏重于事务处理,也就是整数计算。Intel自身没有强大的GPU资源来辅助浮点计算,为了避免产品在竞争中处于不利地位,它不得不赋予CPU同样强大的浮点性能。而今天的AMD就不必如此,它的Radeon HD GPU擅长于浮点处理,除传统的3D渲染外,高清视频加速等重要的PC应用均由它接管,并且未来将具备越来越强的通用计算能力,并成为APU的一部分。既然如此,委实没有太大必要继续为CPU设计更多、更强大的浮点计算单元。这种思路在经济上也是非常合算的:浮点计算单元要占用的晶体管资源比整数单元大得多,如果将浮点单元作精简,那么节约出的资源就可以用于增强整数计算单元,而平台的浮点计算任务则主要依赖GPU来完成。那么,在晶体管总量、工作频率等要素均不变的前提下,整个平台的性能便可以获得显著的增长。
Bulldozer架构便是这种思路的产物。我们在架构图中可以看出,Bulldozer一个模块内拥有2个整数单元,这一点同双核心的Intel Core架构相似;但它却只有一个浮点计算单元,而非常规双核处理器的2个。单纯从运算单元的数量来看,Bulldozer一个模块只能算是1.5核而非双核,被精简的部分就是浮点单元。

图4 Phenom Ⅱ所采用的K10架构
通过图3、图4的对比,我们可以清晰地看到Bulldozer同K10架构(Phenom Ⅱ)的不同,除了具有四路指令解码外,Bulldozer微架构直接为1.5核设计,也就是它比K10架构多了一个整数单元。不过,K10的每个整数单元都是由6个ALU和各一个MUL、DIV运算器构成,且具有64KB的一级数据缓存;而Bulldozer中的整数单元,只包含4个ALU和一个MUL、DIV运算器,另外一级数据缓存的容量也削减到16KB。这其中你会注意到两件事:ALU数量减少,这意味着Bulldozer的单个整数单元实际性能弱于K10,但通过两个单元的合力,Bulldozer终仍将取得明显的性能优势。其次,Bulldozer的一级数据缓存容量显著降低,AMD这么做的理由在于:4发射带来更高的指令效率,而不必一味依赖大的缓存;再者缓存所用的SRAM逻辑是晶体管耗用大户,降低缓存可以令芯片变得小规模化。AMD表示,Bulldozer模块内的第二个整数核心只需占用核心面积的12%尺寸,从芯片设计上讲这只会给整个内核增加5%的电路。因此,这种1.5核的特殊设计,并没有消耗比K10更多的晶体管资源,在同等条件下,Bulldozer架构处理器的制造成本,同样不会高于现行的Phenom Ⅱ,但是性能却可以有相当显著的提升。这一次,我们不得不说AMD干得漂亮,它仅凭借自身IC设计的高超技巧,就达成了提升处理器性能的目标。
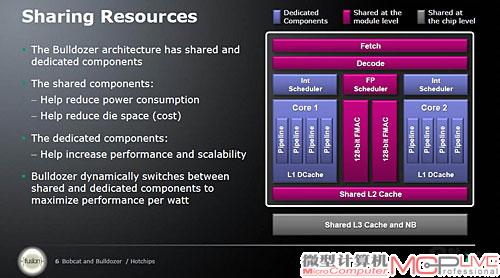
图5 Bulldozer内的浮点单元由两个核心共享,从而获得更出色的能耗和成本优势。
我们接下来对比Bulldozer与K10的浮点单元设计。同样从图3、图4的对比中,你会惊奇地发现这两者的浮点单元设计几乎如出一辙,它们都具有两个MMX运算器和两个128位乘法累加单元(FMAC),结构也没有任何改变。既然如此,我们就不必预期Bulldozer的浮点性能会有多大的增进,它唯一可以指望的就是Bulldozer架构处理器能有更高的工作频率。
1.5核设计的Bulldozer模块采用这样的协作机制:当涉及整数运算时,它是以传统双核处理器的模式进行的—解码指令被分配至两个整数核心,分别运算处理至完毕;这两个核心的协作则是通过共享的二级缓存进行的。而涉及浮点计算任务时,这两个核心其实共同分享着一个浮点单元,其中的两个128位FMAC单元既可以被每个核心单独使用,也可以合并组成一个256位FMAC单元。另外,为了获得大程度的性能功耗比,Bulldozer架构还支持共享、专用单元之间的动态切换。
不论从哪一个角度来看,Bulldozer的设计都相当值得称道,假如我们将目光转移到图形领域,便会发现AMD在过去的两年,便是用小核心加多数量的做法成功地压倒对手,获得市场领先。现在,AMD打算在CPU领域重复这样的做法,尽管产品推出尚需时间,但我们推断Bulldozer大有希望成为又一代经典的微架构。

